 12:40:32 PM MONDAY AUGUST 3, 2026
12:40:32 PM MONDAY AUGUST 3, 2026 THE HACKER NEWS

NickySlicks
2 hours ago
Show HN: Nightcrawler – A local AI pentesting agent running on a smartphone
Local AI powered red teamer on a phone. Contribute to garagehq/nightcrawler development by creating an account on GitHub....
4 DAYS AGO
AUSTINALLEGRO
Train Simulator Controller
6 HOURS AGO
CL42
Situational Awareness and the Impending Stock Market Volatility
3 DAYS AGO
EMILESILVIS
Show HN: A Handwritten Blogging Platform
12 HOURS AGO
TMWNN
CP/M-386 – CP/M for 386 protected mode, derived from CP/M‑68K
6 DAYS AGO
CHB0403085482
Norway became a global salmon behemoth. Now it's facing the consequences
21 HOURS AGO
C-OREILLS
How the words we teach English language learners changed
A DAY AGO
DELICHON
Karpathy’s Pelican
17 HOURS AGO
THEBIGSHIP
My personal AI benchmark: “Generate an SVG of a frog with a Habsburg jaw”
16 HOURS AGO
ARCAEGE
Show HN: Make your Framework 12 sound like a creaky door
10 HOURS AGO
FELINEFLOCK
AI migrated legacy COBOL programs to Java, bugs included
3 HOURS AGO
NUCATUS
EU enforces labeling AI generated content
10 HOURS AGO
FELINEFLOCK
AI migrated legacy COBOL programs to Java, bugs included
A DAY AGO
PROJSCOPE
Meshdiff – visually compare two STL versions in the browser, client-side

KolmogorovComp
4 hours ago
Bonsai: Janestreet's UI Library
A library for building dynamic webapps, using Js_of_ocaml - janestreet/bonsai
paavohtl
6 hours ago
Rust project goals: Immobile types and guaranteed destructors
Rust Project Goals tracker. Contribute to rust-lang/rust-project-goals development by creating an account on GitHub....
nuwandavek
12 hours ago
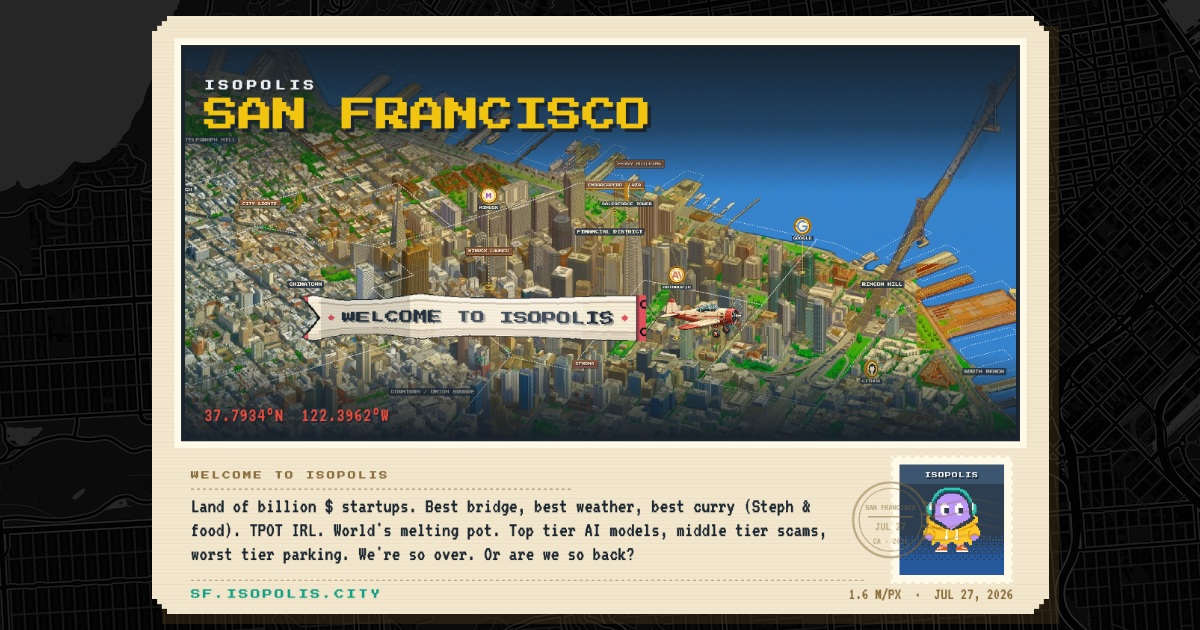
Show HN: Isopolis – Isometric pixel map of SF
San Francisco as one giant isometric pixel painting. Pan the city, open the tours, send a postcard....

uneven9434
4 hours ago
Show HN: We Fixed UniFi's Slow PPPoE Performance with PPPoE Half-Bridge
UniFi gateways (UDM Pro/SE/Pro Max/Beast/EFG) ship with notoriously underpowered CPUs and has no hardware acceleration for PPPoE. Paired with a PPPoE-based ISP connection, the performance is...


nnx
5 hours ago
Octane – React's programming model, compiled
React's programming model, compiled ahead of time. No VDOM, no rules of hooks....


Bender
41 minutes ago
The AI bubble is popping; we just don't know it yet
Weird times in earnings-land, and we're talking about it on The Reg's home grown podcast...


mohamed_am83
4 hours ago
PISIGuard: Protect your personal and sensitive info when you chat with AI
Protect your personal and sensitive info when you chat with AI - mohamed--abdel-maksoud/pisiguard...
BlueBerry2001
an hour ago
ICE Collected Nearly 1M People's DNA Last Year–Including Young Children
Internal documents show ICE's DNA collection has skyrocketed in the second Trump administration. Now hundreds of thousands of people never convicted of a crime are in an FBI criminal databas...
 https://www.wired.com/story/ice-dna-collection-fbi-codis/
https://www.wired.com/story/ice-dna-collection-fbi-codis/
eatonphil
3 days ago
Why we write our own C and C++ inference engines
LocalAI is the open source AI engine. Run any model, LLMs, vision, voice, image and video, on any hardware. No GPU required....

vlad_kalinkin
20 hours ago
Show HN: Kakehashi – Experimental userspace to run macOS binaries on Linux ARM
Userspace macOS translation layer for Linux ARM64. Contribute to wie-project/kakehashi development by creating an account on GitHub....

surprisetalk
6 days ago
Note-Taking and Personal Knowledge Management
Bridge heading into the smokey landscape. License: CC-0 I read Brennan Kenneth Brown's What have note-taking PKMs accomplished, really?......

zdw
7 days ago
Convergence is not enough
Getting into trouble with data representations in Automerge....
speckx
18 hours ago
The myth of Snow Leopard
It was a hot mess, but the myth is useful today....
alephnerd
2 hours ago
The fading American Dream: Visa uncertainty drives Indian tech workers back home
Return migration from the US is rising as visa rules tighten, but India's tech job market is slowing too....

kiyanwang
6 hours ago
The AI Productivity Gap
Why the productivity gains from AI are still small....

graham33
20 hours ago
Show HN: NixOS-DGX-Spark – Nix and NixOS on the DGX Spark
Use Nix and NixOS on your DGX Spark! Contribute to graham33/nixos-dgx-spark development by creating an account on GitHub....